31 Jan, 2010, Davion wrote in the 2nd comment:
JohnnyStarr said:
I know that this is a large undertaking, but it's just for learning / fun.
I realize that the result may not be anything useful, other than a learning experience.
So far I've thought about designing a tiny structure of a language. I want it to be able to
add classes and objects with variables and methods. So far I have decided to go with C for speed, maybe
C++. One of the first things I've thought about is creating primative data types as Objects similar to Ruby.
I dont see much complexity in using some sort of generic style datatype call it OBJECT for now. OBJECT
can be any of the primative types: (string, number, bool, etc), but it can also be any user defined datatype. Each object would have a linked list of PROP *properties, and FUNC *functions.
One of the issues I have is figuring out how I want to store the values of the class / instance variables. Because we are restricted with C's static typing, I had the idea of storing each type as a char* which
would be converted to integer in case of numeric operations, or it would store the ID for the OBJECT
that it was linked to. The alternative I suppose would be for each PROP to have multiple value properties:
Obviously, I have a long way to go. More or less, I would mainly like to have a higher understanding of
how this SHOULD be done.
I realize that the result may not be anything useful, other than a learning experience.
So far I've thought about designing a tiny structure of a language. I want it to be able to
add classes and objects with variables and methods. So far I have decided to go with C for speed, maybe
C++. One of the first things I've thought about is creating primative data types as Objects similar to Ruby.
I dont see much complexity in using some sort of generic style datatype call it OBJECT for now. OBJECT
can be any of the primative types: (string, number, bool, etc), but it can also be any user defined datatype. Each object would have a linked list of PROP *properties, and FUNC *functions.
One of the issues I have is figuring out how I want to store the values of the class / instance variables. Because we are restricted with C's static typing, I had the idea of storing each type as a char* which
would be converted to integer in case of numeric operations, or it would store the ID for the OBJECT
that it was linked to. The alternative I suppose would be for each PROP to have multiple value properties:
struct PROP
{
int number_value;
char * string_value;
OBJECT * obj_value;
};
Obviously, I have a long way to go. More or less, I would mainly like to have a higher understanding of
how this SHOULD be done.
You could always use the 'void' type to store the values. Something like,
struct prop
{ int type;
void * value;
}
You could store pretty much anything in that (with the exception of pointers to functions IIRC). You'd just use a type of switch statement to grab the value.
switch(p->type)
{ case TYPE_INT: i_value = (int)(*value); break;
}
This isn't to say your original approach is bad, or wrong. This is simply another way of doing it. If I were, however, going to do it the way you mentioned, I'd use a union for the values.
struct prop
{ union
{ int number;
char * string;
OBJECT *object;
} value;
int type;
};
This way, all those 'values' share the same memory so your prop struct isn't the size of -every- value type.
31 Jan, 2010, David Haley wrote in the 3rd comment:
You can also use inheritance, e.g., a generic 'Value' class, from which you derive 'IntValue', 'StringValue', etc. This is not hugely different from storing a type number, and a void* to the data in question. But it lets you have more compiler-level type safety; for example you can define some functions that only take 'IntValue' objects as arguments.
You definitely don't want to start storing everything as a 'char*'; you're not as limited as you might think by C's type system. Don't forget that many scripting languages are in fact implemented in C or C++.
Needless to say this is not at all an easy project, but if you want to read more I'd perhaps start with this intro compilers course. For your purposes you can skip the theory of the compilation algorithms but you will need to understand lexing and parsing to some extent, not to mention your eventual runtime system.
You definitely don't want to start storing everything as a 'char*'; you're not as limited as you might think by C's type system. Don't forget that many scripting languages are in fact implemented in C or C++.
Needless to say this is not at all an easy project, but if you want to read more I'd perhaps start with this intro compilers course. For your purposes you can skip the theory of the compilation algorithms but you will need to understand lexing and parsing to some extent, not to mention your eventual runtime system.
31 Jan, 2010, shasarak wrote in the 4th comment:
IMO static typing is the work of the devil, and is the first thing you should get rid of when designing a language.
31 Jan, 2010, JohnnyStarr wrote in the 5th comment:
@David, thanks for the link, this is very interesting and helpful.
31 Jan, 2010, JohnnyStarr wrote in the 6th comment:
So a lexer would break down the lines of code into tokens, and the parser creates a list out of the series of tokens, then the interpreter
would operate on the parsed tokens that are stored in some sort of tree data structure? How might a tree like this look in C? It seems like
a linked list would work, in that you would add each set of instructions, that once computed, would jump to the next set, and so on.
But then I guess you would have to consider scope. Each block of code could potentially have it's own local scope.
I suppose that you would have to create a virtual stack to account for all these things. I know I'm over my head, but I love this stuff.
would operate on the parsed tokens that are stored in some sort of tree data structure? How might a tree like this look in C? It seems like
a linked list would work, in that you would add each set of instructions, that once computed, would jump to the next set, and so on.
if ch.race == "borg" then
os.output("hi!")
end
– so the token list would be
"if" "ch" "." "race" "==" ""borg"" "then" "os" "." "output" "(" ""hi!"" ")" "end"
– then the linked list of operations might look something like this
- if
-> ch.race == "Borg"
-> then
-> os.output("Hi!")
-> end
But then I guess you would have to consider scope. Each block of code could potentially have it's own local scope.
I suppose that you would have to create a virtual stack to account for all these things. I know I'm over my head, but I love this stuff.
31 Jan, 2010, Tyche wrote in the 7th comment:
JohnnyStarr said:
So a lexer would break down the lines of code into tokens, and the parser creates a list out of the series of tokens, then the interpreter
would operate on the parsed tokens that are stored in some sort of tree data structure? How might a tree like this look in C? It seems like
a linked list would work, in that you would add each set of instructions, that once computed, would jump to the next set, and so on.
would operate on the parsed tokens that are stored in some sort of tree data structure? How might a tree like this look in C? It seems like
a linked list would work, in that you would add each set of instructions, that once computed, would jump to the next set, and so on.
No a linklist wouldn't work. At least I've never seen it in any parser I've looked at as the data structure is too simplistic.
Most parsers create trees from the lexer/scanners tokens, usually called AST (abstract syntax trees).
A tree might be walked several times to perform syntactic and/or semantic analysis.
Finally an interpreter walks the tree to execute it or….
a code generator wlaks the tree to generate code (byte code/machine instructions)
The byte code/machine instructions might be examined by an optimizer.
Then saved or fed into a VM or real processor to execute now or later.
I'd recommend taking a good look at CoolMud, if you're looking for examples of implementing a tiny language. It's also a fine example of good C coding, especially when contrasted with spaghetti garbage like Diku.
[link=file]711[/link]
01 Feb, 2010, Scandum wrote in the 8th comment:
Tyche said:
No a linklist wouldn't work. At least I've never seen it in any parser I've looked at as the data structure is too simplistic.
A linked list works fine, just need to store the nesting level in each token, so when an if check is false you skip tokens till the level drops back to the current level. Instead of skipping tokens you can add a pointer to the next valid token, which would create a tree. If you know the number of tokens in advance (or as part of the optimization process) it's probably faster to use an array, and for additional speed you can use index numbers instead of pointers to jump ahead.
Lolahas a mobprog tokenizer, no idea how it compares to CoolMud's scripting language.
01 Feb, 2010, David Haley wrote in the 9th comment:
Yes, why use a tree data structure when you can implement the same thing in a more confusing and clunky manner?
01 Feb, 2010, JohnnyStarr wrote in the 10th comment:
So I'm curious, in an interpreted language, is the AST constructed at runtime?
Do you populate the tree only with what is coded in the script / application?
Is there some maintained list of ASTs that you keep track of for later use?
Do you populate the tree only with what is coded in the script / application?
Is there some maintained list of ASTs that you keep track of for later use?
01 Feb, 2010, David Haley wrote in the 11th comment:
The AST is typically the result of parsing, and potentially after some extra analysis like Tyche referred to. This doesn't have to happen at literal runtime; you can parse a script and store some resulting data structure in a "pre-compile" phase. (You can do this with Lua, for instance, using luac. Python does it too. I'm sure that Ruby has an equivalent. It's pretty common.) Java does this rather extensively where it compiles Java source files to byte code, which is then further interpreted. But in Java you can't run the programs without first compiling them, whereas "scripting" languages usually let you compile them on the fly.
I'm not sure what you mean by populating the tree with what's only in the script/application. The AST is typically some representation of the script you just parsed. So it kind of "is" the script in question.
You don't typically keep around ASTs unless you're doing some kind of storing away of byte code as I mentioned earlier.
I'm not sure what you mean by populating the tree with what's only in the script/application. The AST is typically some representation of the script you just parsed. So it kind of "is" the script in question.
You don't typically keep around ASTs unless you're doing some kind of storing away of byte code as I mentioned earlier.
01 Feb, 2010, JohnnyStarr wrote in the 12th comment:
Ok I see.
What might an AST look like in C?
A struct that contains a pointer to the next node, but also a left and right child node?
In my head I would imagine something like an "If" statement having a left and right child (one for true, one for false).
This way, if the expression is true, then you would ignore the right node, and any children it contains.
EDIT: I found this picture, and it makes the most sense:
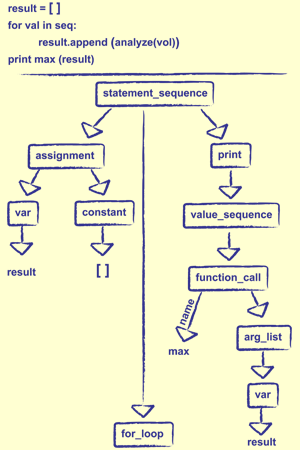
So a tree structure in C might just be a list, but each branch could potentially have unlimted sub branches?
What might an AST look like in C?
A struct that contains a pointer to the next node, but also a left and right child node?
In my head I would imagine something like an "If" statement having a left and right child (one for true, one for false).
This way, if the expression is true, then you would ignore the right node, and any children it contains.
EDIT: I found this picture, and it makes the most sense:
So a tree structure in C might just be a list, but each branch could potentially have unlimted sub branches?
01 Feb, 2010, Runter wrote in the 13th comment:
David Haley said:
Yes, why use a tree data structure when you can implement the same thing in a more confusing and clunky manner?
^^
01 Feb, 2010, David Haley wrote in the 14th comment:
JohnnyStarr said:
So a tree structure in C might just be a list
Please ignore the statement that linked lists work "just fine", you really don't want to go down that route.
A tree data structure is a recursive structure such that each node contains zero or more child nodes. The resemblance to a list is that the children are stored as a list. You really don't want to be thinking about the whole structure as a list.
JohnnyStarr said:
In my head I would imagine something like an "If" statement having a left and right child (one for true, one for false).
This way, if the expression is true, then you would ignore the right node, and any children it contains.
This way, if the expression is true, then you would ignore the right node, and any children it contains.
This is where things get kind of complicated. There is some distinction, in principle, to be made between the parse tree that results from just, well, parsing the code, and then the "execution tree". You do not have to represent your program's execution as a tree. It is however convenient to do so for simple languages. In what you're describing, you can execute the program by walking the tree in a particular fashion. In the example you described, you walk the tree such that if you find an if statement node, you go left or right depending on the truth value of the expression being evaluated.
JohnnyStarr said:
What might an AST look like in C?
A struct that contains a pointer to the next node, but also a left and right child node?
A struct that contains a pointer to the next node, but also a left and right child node?
Well it depends really. Sometimes you have several children, sometimes you might have only one. An if statement would have several children as well; first you'd have the condition expression itself, then the code to execute if it's true, then the code to execute if it's false. A for loop would have several children as well: the initialization expression, the condition, the increment, and then of course the loop itself.
I have an implementation of a fairly simplistic scripting language in Java lying around somewhere. It very naturally translates to C++ if you are so inclined. I'll see if I can post it somewhere at some point.
01 Feb, 2010, Scandum wrote in the 15th comment:
David Haley said:
Please ignore the statement that linked lists work "just fine", you really don't want to go down that route.
JohnnyStarr said:
So a tree structure in C might just be a list
Please ignore the statement that linked lists work "just fine", you really don't want to go down that route.
I wonder what you do when I don't post for a week, beat your girlfriend?
JohnnyStarr said:
What might an AST look like in C?
A struct that contains a pointer to the next node, but also a left and right child node?
In my head I would imagine something like an "If" statement having a left and right child (one for true, one for false).
This way, if the expression is true, then you would ignore the right node, and any children it contains.
A struct that contains a pointer to the next node, but also a left and right child node?
In my head I would imagine something like an "If" statement having a left and right child (one for true, one for false).
This way, if the expression is true, then you would ignore the right node, and any children it contains.
Most tokens will only need a next pointer, so it'd be a waste of memory to give every node a true and false pointer, which is exactly why you wouldn't want to view it as a tree, unless you've never created an AST (like Haley) and are citing Wikipedia mixed in with fancy terms.
You'd probably want to use a different structure for each type, (if/else/break/etc) rather than trying to use a generic structure. I'd also suggest keeping track of the level with an integer first, and optimizing (by creating a tree like structure) later on, ideally using an array as I already suggested since that'll result in the fastest execution and lowest memory usage.
01 Feb, 2010, David Haley wrote in the 16th comment:
Scandum said:
I wonder what you do when I don't post for a week, beat your girlfriend?
Well that was certainly an interesting thing to say.
But hey, if Tyche and I agree on something, it means that either the world is ending or there just might be something to it. Just saying. :rolleyes:
01 Feb, 2010, elanthis wrote in the 17th comment:
Languages, compilers, and runtimes. This is my zone here. I only wish I had the time to give a proper rundown on all the key parts, but alas, I have a pile of assignments to do by tomorrow…
IMO dynamic typing is the work of lazy dumbasses who would rather have a far higher bug count to save themselves a tiny bit of typing and make their code less opaque in the process, and is the last thing you should ever use when designing a language.
Except that requires you to stuff integers into the void* which is kind of confusing, and without using intptr_t just results in non-portable code.
Use a union instead.
Your biggest issue is going to be memory management. The easiest solution is to add a reference counter to every OBJECT, and make _100% sure_ that whenever you store an OBJECT reference anyway, you increment that counter, and that whenever you remove/change the reference, you decrement the counter first (and deallocate if necessary).
The problem with reference counting is that it can create reference cycles that result in a memory leak. This may be acceptable to you; you might just say that you don't want reference cycles and code accordingly. Novice coders (the kind who think dynamic typing is cool because it removes the need for them to understand how to architect software, for example) are going to end up creating cycles without realizing it, though.
A more robust garbage collection technique is not particularly difficult to implement, so long as you don't mix OBJECT data with other native C data. A simple mark-and-sweep collector, for example, does nothing more than call a mark_object function on every OBJECT, which recursively calls mark_object on any children OBJECTS (anything stored in a property tree or an array list, for example). You keep a global linked list of all allocated OBJECTs. The mark_object toggles a gc flag on each object. You then run a sweep_objects function that loops through the global linked list and removes and deallocates any object that does not have its gc flag toggled to the current value (it flips back and forth with each call to sweep). There are far more efficient strategies, but that is where you should start out if you want to avoid the reference cycle problem.
The lexer breaks the text into tokens by recognizing patterns of characters. The parser breaks the tokens into an AST by recognizing patterns of tokens. I highly recommend a hand-written recursive-decent parser. Tools like lex/yacc seem like a great idea at first, but they're just going to hide details away from you and not let you learn them, they're difficult to use without serious issues (memory management of token data, for example), they are slow, and they are incapable of generating high-quality error reporting. Every major compiler has long since moved away from lex/yacc (and their GNU equivalents, flex/bison) precisely because they suck.
A hand-written recursive-decent parser for a simple calculator-like language (without operator precedence) might look something like:
That doesn't build an AST or anything, but might give you a quick idea of how a parser is structured. There are of course many excellent articles on the topic of language design and the generalities of recursive-decent parsers, which I suggest you Google. There are other parsing strategies you might consider, but IMO recursive-decent is the easiest to understand and easiest to write. You do need to design your language to be easy to parse that way, though.
And I hold her still. Because using a linked list for an AST is fucking stupid and makes performing any kind of useful semantic analysis or transformation of the AST a pain in the ass compared to just doing it right. But hey, what do I know, it's not like I work on compilers or anythi-oh wait a minute I do. :/
Depends on the type of tree. A binary tree is not a list, for example, it would be nodes with two and exactly two children. For an AST, you're going to have some different kinds of nodes; a unary operator node only needs one child, a binary operator node needs two children, and something like an if node would need three (one for the conditional expression, one for the truth block, and one for the false block).
You REALLY need to go study up basic algorithms before trying to implement a script language. The question of what a tree is or what it looks it is CS101 material, and you can't really get very far without understanding that kind of stuff. Even just hitting Wikipedia and reading up on various flavors of tree will do you a world of good (and make you more useful than most professionals I end up working with, sadly).
Maybe, or maybe not. The general gist of a compiler is a pipeline that looks something like so:
source -> lexer -> parser -> AST -> semantic analysis -> high-level optimization -> SSE lowering -> low-level optimization -> machine code transformation -> machine optimization -> final machine code
An interpreted languages also needs an interpreter, of course, which is basically software that executes the "final machine code" (which is usually called byte code with interpreters).
That said, a lot of languages skip various parts of that pipeline. Some script languages for example directly execute statements in the parser stage, such as UNIX shell script. The vast majority of script languages do not have an SSE or machine code transformation stage, instead translating directly from the AST into the final byte code representation. Some very popular script languages such as Lua do not even have an AST, but instead generate the byte code during the parser stage, while other popular script languages like pre-1.9 versions of Ruby do not have any form of byte code, but directly interpret the AST.
A good but simple script language will probably have a pipeline something like:
source -> lexer -> parser -> AST -> semantic analysis/optimization -> byte code
The need for "semantic analysis" may be very small in many simple script languages. The gist of what that does is that the parser just makes sure that the raw grammar of the source is correct but it doesn't validate that the actual expressions are valid. For example, if you have a -> operator that looks up properties in an object, and your numbers are not treated as objects in your language and the property names must be identifiers, then an expression like:
3->"foo"
is valid grammar (unless you specified your grammar in a very unnecesasrily complex fashion) but invalid semantically. Your semantic analysis is what sees that and reports an error that -> does not operate on integers and does not take a string.
The optimization phase can be rolled into semantic analysis so long as you only want simple optimization, like very basic constant folding and dead code elimation. Constant folding is when the compiler sees code like
3+3
and compiles that directly into a single value 6, instead of executing an ADD operation during script execution. Dead code elimination is when it sees code like:
if (3 > 0) foo() else bar()
and see that 3 > 0 is always true and just slaps in the true block's body instad of the whole comparison and false block (which cuts down the code generated in the bytecode and removes an unnecessary comparison during execution). There are a few other simple optimizations you can perform on the AST, but most really good optimizations require a better form like SSE. You don't generally parse directly to SSE though because doing semantic analysis is far easier on an AST than SSE. (I won't try to explain SSE here, you _really_ need a solid foundation in CS, data structures, and algorithms to grok it – it's not really used in script engines generally, though, so don't worry too much about it.)
Once your AST is validated, you then recursively iterate through it and generate some kind of byte code. Byte code can take several forms, but generall it's a series of opcode numbers followed by operands. If you have familiarity with assembly language, you should understand the gist of what bytecode looks like.
I highly recommend going for a stack-oriented interpreter if this is your first try. A register machine is not much harder, and is a little easier in some ways, but there's a lot more text online about how to implement a stack-oriented interpreter and you'll find more help via Google if you go that route.
Basically, your bytecode is a series of operations. A compiled function is just an array of these operations. You execute operations by iterating over the array. You implement things like conditionals and loops using references to other blocks of bytecode (and execute them recursively) or compile the whole function into a single block and use compare-and-branch operations. In the latter route (the more complex one), a while loop like so:
while (foo > 3) { bar(); foo = foo - 1; }
might be compiled something like:
0 LOOKUP foo
1 PUSH_INT 3
2 GREATER_THAN
3 BRANCH_IF_FALSE 14
4 POP
5 LOOKUP bar
6 INVOKE 0
7 POP
8 LOOKUP foo
9 PUSH_INT 1
10 SUBTRACT
11 STORE foo
12 POP
13 BRANCH 0
14 POP
The bytecode is a series of numbers, more or less. The number on the left is the index into the bytecode array (fudged a bit). The data to the right of an opcode is an operand, which is also stored in the bytecode array. You have to decode these yourself. The reason this is harder is that you have to figure out the indexes to jump to for your BRANCH* opcode, which takes a little work. The interpreter will be faster going this route, but will be easier to write and debug if you use a recursive approach to dealing with loops. I've used both approaches depending on the efficiency requirements I had to work within and the time/effort I felt like putting into the implementation.
If you happen to be in the Seattle area, I'd be more than happy to meet up and go over a lot of the finer details and implementation strategies. I can explain things way more clearly and concisely when I have a whiteboard handy (greatest invention of mankind ever).
Quote
IMO static typing is the work of the devil, and is the first thing you should get rid of when designing a language.
IMO dynamic typing is the work of lazy dumbasses who would rather have a far higher bug count to save themselves a tiny bit of typing and make their code less opaque in the process, and is the last thing you should ever use when designing a language.
Quote
You could always use the 'void' type to store the values. Something like,
Except that requires you to stuff integers into the void* which is kind of confusing, and without using intptr_t just results in non-portable code.
Use a union instead.
enum TYPE_TAG {
TYPE_VOID,
TYPE_NUMBER,
TYPE_STRING,
TYPE_OBJECT
};
struct OBJECT {
enum TYPE_TAG tag;
union {
int number;
char* string;
OBJECT* object;
} d;
};Quote
Obviously, I have a long way to go. More or less, I would mainly like to have a higher understanding of
how this SHOULD be done.
how this SHOULD be done.
Your biggest issue is going to be memory management. The easiest solution is to add a reference counter to every OBJECT, and make _100% sure_ that whenever you store an OBJECT reference anyway, you increment that counter, and that whenever you remove/change the reference, you decrement the counter first (and deallocate if necessary).
The problem with reference counting is that it can create reference cycles that result in a memory leak. This may be acceptable to you; you might just say that you don't want reference cycles and code accordingly. Novice coders (the kind who think dynamic typing is cool because it removes the need for them to understand how to architect software, for example) are going to end up creating cycles without realizing it, though.
A more robust garbage collection technique is not particularly difficult to implement, so long as you don't mix OBJECT data with other native C data. A simple mark-and-sweep collector, for example, does nothing more than call a mark_object function on every OBJECT, which recursively calls mark_object on any children OBJECTS (anything stored in a property tree or an array list, for example). You keep a global linked list of all allocated OBJECTs. The mark_object toggles a gc flag on each object. You then run a sweep_objects function that loops through the global linked list and removes and deallocates any object that does not have its gc flag toggled to the current value (it flips back and forth with each call to sweep). There are far more efficient strategies, but that is where you should start out if you want to avoid the reference cycle problem.
Quote
So a lexer would break down the lines of code into tokens, and the parser creates a list out of the series of tokens, then the interpreter
would operate on the parsed tokens that are stored in some sort of tree data structure?
would operate on the parsed tokens that are stored in some sort of tree data structure?
The lexer breaks the text into tokens by recognizing patterns of characters. The parser breaks the tokens into an AST by recognizing patterns of tokens. I highly recommend a hand-written recursive-decent parser. Tools like lex/yacc seem like a great idea at first, but they're just going to hide details away from you and not let you learn them, they're difficult to use without serious issues (memory management of token data, for example), they are slow, and they are incapable of generating high-quality error reporting. Every major compiler has long since moved away from lex/yacc (and their GNU equivalents, flex/bison) precisely because they suck.
A hand-written recursive-decent parser for a simple calculator-like language (without operator precedence) might look something like:
/* parse a file, which is a series of math expressions */
int parse_file(void) {
/* loop until we hit the end of the file */
while (!token_accept(TOKEN_EOF)) {
/* if we have an empty line, that's just fine */
if (token_accept(TOKEN_NEWLINE)) {
/* nothing to do */
}
/* we expect a valid expression, error if we don't get one */
if (!parse_expr()) {
return 1;
}
}
/* parsed fine */
return 0;
}
/* parse an expression */
int parse_expr(void) {
/* expect a terminal value */
if (!parse_terminal()) {
return 1;
}
/* expect zero or more binary operators */
while (token_accept(TOKEN_ADD) || token_accept(TOKEN_SUBTRACT)) {
/* need another terminal after each operator */
if (!parse_terminal()) {
return 1;
}
}
return 0;
}
That doesn't build an AST or anything, but might give you a quick idea of how a parser is structured. There are of course many excellent articles on the topic of language design and the generalities of recursive-decent parsers, which I suggest you Google. There are other parsing strategies you might consider, but IMO recursive-decent is the easiest to understand and easiest to write. You do need to design your language to be easy to parse that way, though.
Quote
I wonder what you do when I don't post for a week, beat your girlfriend?
And I hold her still. Because using a linked list for an AST is fucking stupid and makes performing any kind of useful semantic analysis or transformation of the AST a pain in the ass compared to just doing it right. But hey, what do I know, it's not like I work on compilers or anythi-oh wait a minute I do. :/
Quote
So a tree structure in C might just be a list, but each branch could potentially have unlimted sub branches?
Depends on the type of tree. A binary tree is not a list, for example, it would be nodes with two and exactly two children. For an AST, you're going to have some different kinds of nodes; a unary operator node only needs one child, a binary operator node needs two children, and something like an if node would need three (one for the conditional expression, one for the truth block, and one for the false block).
You REALLY need to go study up basic algorithms before trying to implement a script language. The question of what a tree is or what it looks it is CS101 material, and you can't really get very far without understanding that kind of stuff. Even just hitting Wikipedia and reading up on various flavors of tree will do you a world of good (and make you more useful than most professionals I end up working with, sadly).
Quote
Is there some maintained list of ASTs that you keep track of for later use?
Maybe, or maybe not. The general gist of a compiler is a pipeline that looks something like so:
source -> lexer -> parser -> AST -> semantic analysis -> high-level optimization -> SSE lowering -> low-level optimization -> machine code transformation -> machine optimization -> final machine code
An interpreted languages also needs an interpreter, of course, which is basically software that executes the "final machine code" (which is usually called byte code with interpreters).
That said, a lot of languages skip various parts of that pipeline. Some script languages for example directly execute statements in the parser stage, such as UNIX shell script. The vast majority of script languages do not have an SSE or machine code transformation stage, instead translating directly from the AST into the final byte code representation. Some very popular script languages such as Lua do not even have an AST, but instead generate the byte code during the parser stage, while other popular script languages like pre-1.9 versions of Ruby do not have any form of byte code, but directly interpret the AST.
A good but simple script language will probably have a pipeline something like:
source -> lexer -> parser -> AST -> semantic analysis/optimization -> byte code
The need for "semantic analysis" may be very small in many simple script languages. The gist of what that does is that the parser just makes sure that the raw grammar of the source is correct but it doesn't validate that the actual expressions are valid. For example, if you have a -> operator that looks up properties in an object, and your numbers are not treated as objects in your language and the property names must be identifiers, then an expression like:
3->"foo"
is valid grammar (unless you specified your grammar in a very unnecesasrily complex fashion) but invalid semantically. Your semantic analysis is what sees that and reports an error that -> does not operate on integers and does not take a string.
The optimization phase can be rolled into semantic analysis so long as you only want simple optimization, like very basic constant folding and dead code elimation. Constant folding is when the compiler sees code like
3+3
and compiles that directly into a single value 6, instead of executing an ADD operation during script execution. Dead code elimination is when it sees code like:
if (3 > 0) foo() else bar()
and see that 3 > 0 is always true and just slaps in the true block's body instad of the whole comparison and false block (which cuts down the code generated in the bytecode and removes an unnecessary comparison during execution). There are a few other simple optimizations you can perform on the AST, but most really good optimizations require a better form like SSE. You don't generally parse directly to SSE though because doing semantic analysis is far easier on an AST than SSE. (I won't try to explain SSE here, you _really_ need a solid foundation in CS, data structures, and algorithms to grok it – it's not really used in script engines generally, though, so don't worry too much about it.)
Once your AST is validated, you then recursively iterate through it and generate some kind of byte code. Byte code can take several forms, but generall it's a series of opcode numbers followed by operands. If you have familiarity with assembly language, you should understand the gist of what bytecode looks like.
I highly recommend going for a stack-oriented interpreter if this is your first try. A register machine is not much harder, and is a little easier in some ways, but there's a lot more text online about how to implement a stack-oriented interpreter and you'll find more help via Google if you go that route.
Basically, your bytecode is a series of operations. A compiled function is just an array of these operations. You execute operations by iterating over the array. You implement things like conditionals and loops using references to other blocks of bytecode (and execute them recursively) or compile the whole function into a single block and use compare-and-branch operations. In the latter route (the more complex one), a while loop like so:
while (foo > 3) { bar(); foo = foo - 1; }
might be compiled something like:
0 LOOKUP foo
1 PUSH_INT 3
2 GREATER_THAN
3 BRANCH_IF_FALSE 14
4 POP
5 LOOKUP bar
6 INVOKE 0
7 POP
8 LOOKUP foo
9 PUSH_INT 1
10 SUBTRACT
11 STORE foo
12 POP
13 BRANCH 0
14 POP
The bytecode is a series of numbers, more or less. The number on the left is the index into the bytecode array (fudged a bit). The data to the right of an opcode is an operand, which is also stored in the bytecode array. You have to decode these yourself. The reason this is harder is that you have to figure out the indexes to jump to for your BRANCH* opcode, which takes a little work. The interpreter will be faster going this route, but will be easier to write and debug if you use a recursive approach to dealing with loops. I've used both approaches depending on the efficiency requirements I had to work within and the time/effort I felt like putting into the implementation.
If you happen to be in the Seattle area, I'd be more than happy to meet up and go over a lot of the finer details and implementation strategies. I can explain things way more clearly and concisely when I have a whiteboard handy (greatest invention of mankind ever).
01 Feb, 2010, David Haley wrote in the 18th comment:
elanthis said:
There are other parsing strategies you might consider, but IMO recursive-decent is the easiest to understand and easiest to write. You do need to design your language to be easy to parse that way, though.
Yes, it is the easiest to write and understand. But that second sentence is where the rub is, really: until you have some experience with language design, parsing and syntax, I think it's difficult to understand what exactly it means to design your language to be easy to parse.
lex/yacc (& friends), for all their faults (and there are indeed many) are a pretty good way to jump-start a compiler project by making the lexing/parsing phase pretty easy. There are more than enough things to be dealt with when writing a language; parsing and lexing is just a small portion of it all. Yes, details are hidden, but those might not be details you care about, either, depending on what you're trying to do.
elanthis said:
Except that requires you to stuff integers into the void* which is kind of confusing, and without using intptr_t just results in non-portable code.
You wouldn't stuff an int into the void*, you'd make the void* point to an int.
Needless to say, this is very complicated stuff. You've ventured into an area of programming that isn't just fun and games anymore and requires some fairly serious understanding of the underpinnings of what's going on (and that's without even getting into the computational theory of parsing). I pointed you to an intro compilers course, but to be fair people only take that after having taken a year's worth of other courses. This is fun but hard stuff, so be prepared to make many false starts. I consider the Java code I referred to, for example, to have several issues and I would do things differently now. But it's vastly superior to my many initial attempts at writing scripting languages. And those were made after having been programming for years already, and even after having taken a (relatively straightforward) compilers intro course. (It was straightforward enough that I had to retake it after I transferred.)
01 Feb, 2010, elanthis wrote in the 19th comment:
… and everywhere I said SSE I meant SSA. Sorry, I'm up to my eyeballs in graphics vector/matrix code right now and am getting my acronyms confused. ;)
02 Feb, 2010, Scandum wrote in the 20th comment:
elanthis said:
And I hold her still. Because using a linked list for an AST is fucking stupid and makes performing any kind of useful semantic analysis or transformation of the AST a pain in the ass compared to just doing it right. But hey, what do I know, it's not like I work on compilers or anythi-oh wait a minute I do. :/
Amazing you have the insight to see that it can be done, this rates you slightly above Haley. Have fun holding her still!
Random Picks

I realize that the result may not be anything useful, other than a learning experience.
So far I've thought about designing a tiny structure of a language. I want it to be able to
add classes and objects with variables and methods. So far I have decided to go with C for speed, maybe
C++. One of the first things I've thought about is creating primative data types as Objects similar to Ruby.
I dont see much complexity in using some sort of generic style datatype call it OBJECT for now. OBJECT
can be any of the primative types: (string, number, bool, etc), but it can also be any user defined datatype. Each object would have a linked list of PROP *properties, and FUNC *functions.
One of the issues I have is figuring out how I want to store the values of the class / instance variables. Because we are restricted with C's static typing, I had the idea of storing each type as a char* which
would be converted to integer in case of numeric operations, or it would store the ID for the OBJECT
that it was linked to. The alternative I suppose would be for each PROP to have multiple value properties:
Obviously, I have a long way to go. More or less, I would mainly like to have a higher understanding of
how this SHOULD be done.